NIPS 2017
I'm continuing my tradition of summarising conferences I attend. Previous posts: NIPS 2016, NIPS 2015, AAAI 2016, ICML 2016. I also went to AAAI 2017 to present my work on unitary recurrent neural networks, but didn't write a summary.
This was my third time attending NIPS, but my first time attending NIPS with jetlag. The advantage of jetlag is that it provides a topic of small talk less agonisingly self aware than the weather (weather readily avoided by waking up at 6am). The downside of jetlag is me standing glassy-eyed in front of a poster, trying to formulate intelligent thoughts but just yawning really, really obviously.
After a few days of complaining about the jetlag I realised I was probably exhausted because NIPS is exhausting. The problem is early mornings, listening to talks, bumping into people I know, talking to people I don't know, having meetings, talking to recruiters, talking over dinner, going to poster sessions, talking at posters, finding people who I had previously talked to as strangers but who are now acquaintances and talking to them again, and so on. Having gone twice before did not teach me moderation, and I was hoarse by Thursday. I also experienced an interesting fluctuation in my desire to do research, which I have depicted in the following graph: (enthusiasm has since returned, luckily)
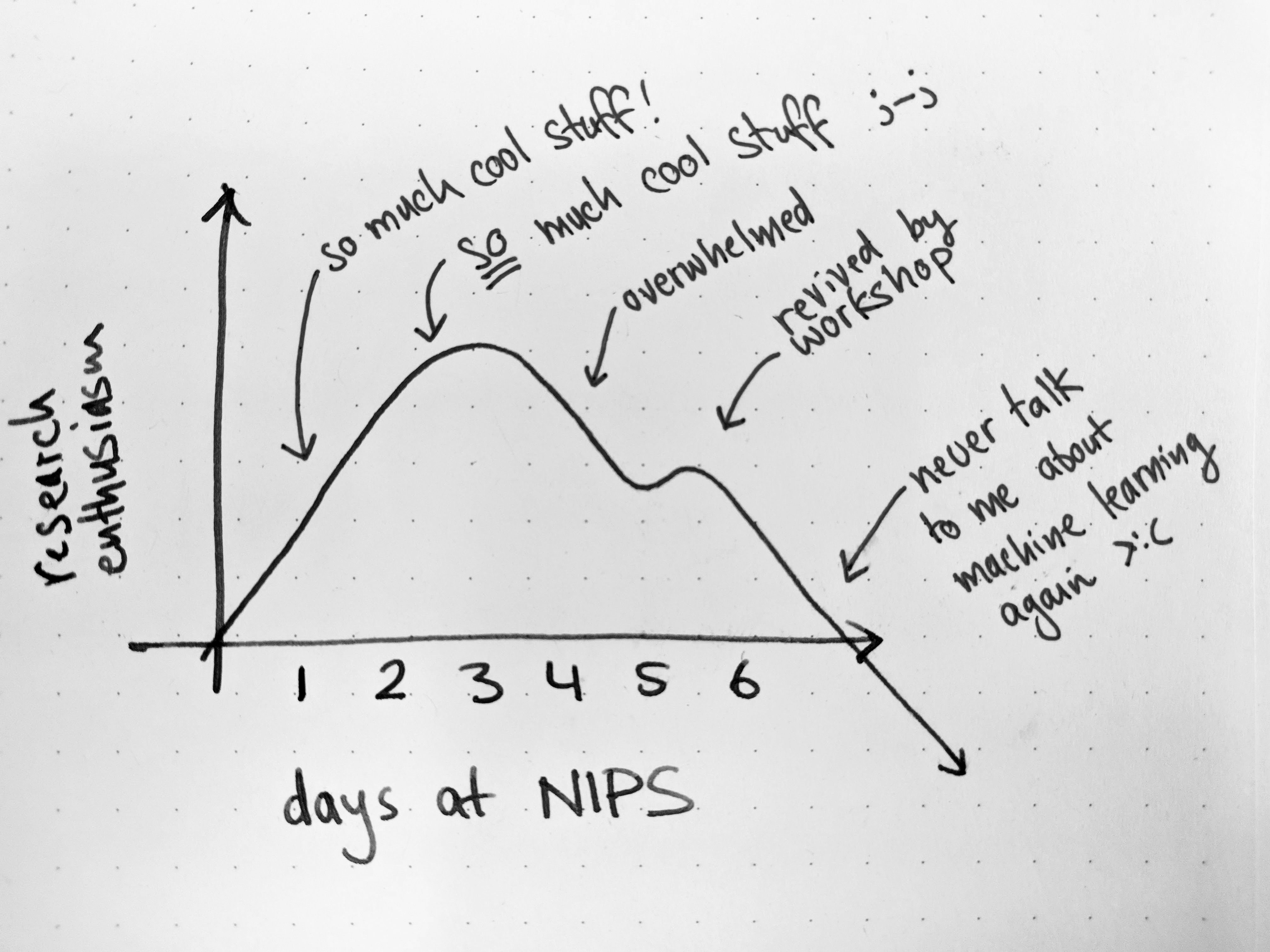
This analysis clearly indicates that the optimal length of NIPS (including tutorials and workshops) is three days. Recent work (private communication) suggests that "taking breaks" can prolong the research-excitement peak, sustaining the individual beyond the end of the conference, providing hope for 2018. When I got back to Zurich I slept for 7 hours, arose for 7 (during which time I did a roller derby exam, but that's another blog post), then went back to bed for another 10. My body had no idea what was going on.
As in 2016, I'll organise this by topic. This post is rather long, but each section is largely independent so feel free to pick and choose.
- Tutorials
- Women in Machine Learning
- Main Conference
- Machine Learning for Health
- Conclusion
Tutorials
The first day of WiML actually coincided with the tutorials, so I was only able to attend those in the morning. I went to A Primer on Optimal Transport. I then got Baader-Meinhof'd about it for the rest of the conference.

I was twenty minutes late to the tutorial. This is decided to commute to the conference on roller skates (see frame from snapchat selfie video, right), and on the first day I misjudged how long it would take (my Airbnb was about 3 miles away).
Unfortunately missing the start of a tutorial, especially a mathematical tutorial, can be fatal. I arrived in the middle of an explanation of how Kantorovich's formulation of optimal transport relates to Monge's formulation and I had no reference for what was going on. I tried to sneakily look things up on Wikipedia to catch up, but all was lost and I came away from the tutorial with only an intuitive understanding of the optimal transport problem, and that Wasserstein barycentres are better than l2 averages for combining distributions, usually. In case you missed it, here are the slides (pdf). I said to myself that I'd go and learn optimal transport real quick and give a coherent summary of it here, but I also want to write this post before I graduate.
Women in Machine Learning Workshop
WiML took place on the tutorial day (Monday), and also on symposia day (Thursday). I am not sure why they split it up like this.
Last year I said that 15% of the 6000 NIPS attendees were women. I don't recall them releasing statistics about attendee demographics this year, but apparently 10% of unique authors amongst submissions were women (amongst accepted submissions? unknown), so the gender situation in ML is still pretty dire. Fixing this is a hard problem and not really my area of expertise (except for what I know from invariably being involved in conversations about Women in STEM), but I'm pretty sure events like this help. Why do I think that? Well, this year was the first instance of the Black in AI workshop, and while I didn't attend (I was at the healthcare workshop), even seeing people tweeting about it made me way more aware of the work being done by Black researchers. So hopefully WiML also alerts people to the existence of good work getting done by women. Oh, and travel grants! I could imagine in this era of NIPS-selling-out-rapidly that pre-purchasing tickets to redistribute to minority groups could also play a part in promoting diversity. Weird to think of women as minority group, but apparently we only comprise 49.58% of the world's population these days.
Interesting talks/posters:
-
(contributed talk) Peyton Greenside spoke about using graph convolutional networks to model Hi-C and also ATAC-seq data. I wanted to talk to her at the poster session, and once again (this happened last year too) her poster was on the other side of the board to mine. You can find her talk at 1:14 into this video.
-
(invited talk) Joelle Pineau spoke about Improving health-care: challenges and opportunities for reinforcement learning. The talk focused on slow and small research: research with small sample sizes, acquired slowly. She spoke about designing treatment strategies for epilepsy, probably referencing this paper: Adaptive Control of Epileptiform Excitability in an in vivo Model of Limbic Seizures (or this one but I can't find the PDF). The idea is that brain stimulation can prevent seizures (cool!), and you can use reinforcement learning to build a controller (controlling the frequency of applied stimulation) to achieve the same level of seizure control while minimising the required amount of stimulation. One lesson she highlighted from this work is that models (in the 'animal model' sense) are important (they use a seizure model from mouse brain cells, I think), and having existing baselines to build from also helps. She also described some work on bandits to do cancer treatment optimisation, which I think I actually already wrote about in my ICML 2016 post.
-
(invited talk) Nina Mishra spoke about Time-Critical Machine Learning. She spoke about anomaly detection on huge streams of data, using Random Cut Forests, and she spoke about machine learning in medical emergencies (probably this paper: Time-Critical Search). When faced with a medical emergency, people will ring the relevant emergency number, and then, a lot of people will turn to Google for help. This isn't always the most efficient way to get useful information, so they did some work on trying to detect (using search query and other metadata such as time, location, query history) whether or not a person was in an emergency situation, with the intention to give more relevant results. Someone asked if it wouldn't be easier to just make a special emergency-search app, but Nina pointed out that nobody wants to download an app in an emergency situation. (I do wonder if phones could come with such an app by default, but making that standard is a whole other challenge). She did however describe a possible emergency app, which I think was called Samaritan (reminding me of the very cool GoodSAM app), that guides a user through performing CPR. Part of the procedure involves putting the phone on the person's chest and using its accelerometer to guide CPR compressions. Nice use of ubiquitous smartphone tech.
Regarding the poster sessions, I spent all of the Monday session presenting my poster (see the Healthcare workshop below), and much of the Thursday session talking at my friend's poster (Learning the Probability of Activation in the Presence of Latent Spreaders) and sneaking peeks at the Interpretable Machine Learning symposium - video of a panel session here, and video of the debate here.
Roundtables
As in previous years, the roundtables were one of the highlights of WiML for me. It's a great opportunity to meet senior scientists I might not otherwise be able to, and also to get to know some of the other WiML attendees.
I ended up going to four tables - two career-based, two topic-based:
-
Choosing between academia and industry - I went to the same topic last year, but this time the table mentors were both in academia, so I got a somewhat different perspective. This is also a question I've spoken to people about and thought about, so I didn't learn much, but it's useful to have one's thoughts externally validated. The gist is that academia gives more freedom, at the cost of stability, potentially having to teach, having to supervise students, and having to
beg for moneywrite grants. Not all of these are necessarily negatives - some people like teaching and supervising (nobody likes writing grants). Meanwhile, industry may limit research freedom, but provides more stability, and (usually) freedom from having to run your own lab with all that entails. -
Establishing collaborators/long-term career planning - the roundtable I attended wasn't especially enlightening on this topic, but the talk from Raia Hadsell touched on it, and gave some good long-term career advice. The advice was this (taken from one of her slides):
- If you like to go deep, make some room for novelty and risk.
- If you are a renaissance woman, try going deep.
- NIPS and WiML are your community - be a participant.
- speak loudly. ask questions. be strong
I'd not self-identify as a 'renaissance woman' (I go for 'attempted polymath'), but I tend to aim for multifaceted (see the name of this website), so the advice to go deep was hard to hear, and therefore useful. (I just love when people tell me things I don't want to hear, it's why I use twitter.)
-
Generative models - a lot of this roundtable consisted of me discussing evaluation of GANs with Ian Goodfellow. This was a bit selfish because it's a topic of direct relevance to my current work on recurrent GANs for medical data (see also below) and maybe less interesting to others. However, I also think evaluation is one of the most interesting GAN-related questions right now. There's understandably a lot of focus on the GAN objective and optimisation procedure, thinking about convergence and stability and so on, but optimisation without evaluation seems foolish.
-
Machine learning for healthcare - we discussed some of the big challenges facing MLHC, like data sharing, causality, and something else I've forgotten but lists should always contain three elements. I've not worked on causality before, but I'm increasingly aware of how causal reasoning (especially counterfactual reasoning) plays a role in trying to understand observational medical data. More about healthcare in the section on the healthcare workshop.
The Main Conference
Invited Talks

John Platt spoke about Powering the next 100 years (video), which was less environmentalist than I was hoping, and more about economics (also important, less exciting). He also spoke about nuclear fusion, which is very exciting, and possibly important (in the future). One issue I had with the premise of this talk is that I don't think we should be trying to expand US power usage to the rest of the world - the US uses disproportionately much energy relative to other developed nations (even with high standards of living, see also the 2000-watt society), so while it would be nice if we could, I would personally rather focus on minimising our energy consumption until it is sustainable to consume more. But anyway, assuming the premise, they use machine learning to optimise both the economics of power usage, and for identifying promising (and safe) experiments to run on fusion reactors.
I missed Brendan Frey's talk about reprogramming the human genome, and also Ali Rahimi's talk for the Test of Time Award. I sorely regret missing the latter talk because people kept asking me about it. I had to wait until I got back to Zurich to rectify the matter, but having now watched it (available here), I get the fuss.
So, regarding Rahimi's talk: Yann LeCun quickly posted a response, and Ferenc Huszár posted another response, and I should make a separate blog post to add my incredibly important opinions on the matter, but I'll just cram them right in here. Ali Rahimi's talk claimed that much of machine learning these days is alchemy - people are building models that work, seemingly by magic, which we don't quite understand. As a relative newcomer (remember, only my third NIPS) I can't hark back to any golden days of rigour and understanding, but I can certainly say that the things he suggested - simple experiments, simple theorems - are appealing.
My take: We should not make unsubstantiated claims in science. We should design experiments to test claims we make about our models, and we should not accept speculatory claims from others as fact. How often do papers today fail by these measures? Rahimi's talk implies this happens often enough to be worth calling out. I feel like I have read papers which make unsubstantiated claims, or over-explain their results, or introduce poorly-defined concepts, but I can't recall any to mind, so my claim must remain purely speculative.
What really resonated with me from Rahimi and also Huszár's points is that empiricism does not imply lack of rigour. A lot of what I do is quite empirical. A lot of what I do is somewhat applied. I've struggled with feeling like it's less scientific as a result. I've felt like I am "just" doing engineering. But the best way I have come to understand this work, which was captured in this point about empiricism, is that rigour does not need to be mathematical (forgive me, I am a former theoretical physicist, so this has taken me some time to realise). Experimental design is also rigorous when done well. Building a model to solve a problem may be a kind of engineering, but trying to understand it afterwards, forming hypotheses about its behaviour and then testing them - this can, and indeed should, be done rigorously. Otherwise, you show that a model exists which can achieve a certain performance on a certain task on a certain dataset, and little else.
The next talk I actually attended was The Trouble with Bias from Kate Crawford (video here). This was a great talk, and I'm glad it got a prime spot in the program. Not only was her public speaking skill commendable (the slides just vanished near the end and she barely skipped a beat), but the talk was really interesting. I admit I was worried I'd already know most of the contents, since I read things about bias on a semi-regular basis (somehow). Even if I'd known everything she was going to say (which I didn't), I'd consider this talk a good distillation and overview of the pressing issues. She made an illuminating distinction which I shall now paraphrase.
When it comes to bias, there are harms of allocation and harms of representation. Biased allocation is easy to see - someone got a loan someone else didn't, someone got bail and someone else didn't, etc. These are concrete and tangible, immediate, and easy to quantify. Representation on the other hand relates to impressions and stereotypes. Google searches for 'CEO' returning all white men is a representational bias, and its effect is much harder to measure. Images of Black people being labelled as 'gorillas' is representational bias and while clearly hurtful, the impact of allocation is not immediately obvious. Many people generally accept that this kind of representation is bad, but can we blame it for any particular instance of allocation bias? Usually not. Representational bias is diffuse across culture, difficult to measure, and may not have any immediately obvious impacts. An example from me: We as a society are starting to suspect that something about how women are represented in society may be influencing the rates of women going on to study STEM subjects. This representational bias may be slowly manifesting as a tangible absence of female engineers, but it is difficult to formalise or prove that these observations are causally related. And of course, machine learning algorithms (like literally any algorithm) can be biased in either of these ways (and presumably more). Once again: watch the talk.
Pieter Abbeel spoke about Deep Learning for Robotics - really, (deep) reinforcement learning for robotics. Probably the most important takeaway from this talk was the 1 second clip of Dota 2 1v1 mid he showed, establishing an important moment in both Dota 2 and NIPS keynote history. The non-Dota content of the talk was largely focused about meta-reinforcement learning, or 'learning to reinforcement learn', and architectures to achieve this. The idea is that you want to build agents which can adapt quickly to new environments, as humans do. One interesting idea was 'Hindsight Experience Replay', which assumes whatever ended up happening was actually the goal, and deriving reward from that.

This converts the usually sparse reward in RL to plentiful reward signals, given the Q-function is augmented with a notion of a goal. He used the cake metaphor that everyone loved from Yann LeCun's keynote at NIPS last year, converting the cherry on top of a cake to multiple cherries on a cake. People can't get enough of the cake joke. It's Portal all over again.
I missed the talks from Lise Getoor, Yael Niv, and Yee Whye Teh because there is only so much time in a day.
Spotlights and Orals
First, a brief rant.
I was quite impressed by the quality of the spotlights and orals this year. Coming from the rather low bar of 'mumbling at a slide covered in equations' of previous years, I was glad to see that many presenters really put time into preparing their talk. These talks give people the opportunity to explain their work to potentially thousands of fellow researchers, so giving a terrible talk is insulting both to the audience and to the people who didn't get that opportunity.
I've thought about the implications of having an additional selection process for determining orals and spotlights. There's a trade-off between highlighting really good papers (with possibly terrible speakers) and highlighting less meritorious work (with a good communicator). There's also a challenge of being fair to non-native English speakers when assessing presentation quality - it would not be acceptable to condemn a talk on the basis of the speaker's command of English.
I try to assess talks by how much they have considered the audience - considering what the audience already knows, what may be obvious (or not, usually), what the really important things in the work are, and what can be skipped without degrading the story. But how to do this without (subconsciously) judging the fluency of the speaker's language and delivery is not entirely clear. I'm sure there is already bias in how the quality of one's English influences paper acceptance (either through clarity or unknowingly discriminatory reviewers), so adding an additional layer on the presentation quality may exacerbate the issue. On the other hand, communication is really important for scientists, and the conference should do what they can to ensure the content is high quality. Maybe some sort of (optional) pre-conference speaking workshop for those invited to give orals and spotlights?
Ranting aside, a selection of talks I took note of:
-
Bayesian Optimisation with Gradients - Jian Wu, Matthias Poloczek, Andrew Gordon Wilson, Peter I. Frazier. Augment Bayesian optimisation using gradient information - 'derivative-enabled knowledge-gradient (dKG)'. They put a Gaussian process prior over the function to be optimised, resulting in a multi-output GP for both function and gradient (the gradient of a GP is a GP). It works better than methods not using derivatives, but I rarely have access to derivatives when I'm doing hyperparameter optimisation in deep networks, so I'm not sure how useful it would be for me.
-
A Unified Approach to Interpreting Model Predictions - Scott Lundberg, Su-In Lee. The framework is called 'SHAP' (SHapley Additive exPlanations). The idea is to interpret the model by assigning features importance values for a given prediction. This work unifies six existing methods by proposing a notion of a 'additive feature attribution method'. They also find that their approach agrees well with human-derived feature attribution scores.
-
Convolutional Gaussian Processes - Mark van der Wilk, Carl Edward Rasmussen, James Hensman. They consider a patch-response function, which maps from image patches to real values, and place a Gaussian process prior on this function. Considering the sum of the patch-response function on all patches of the image as another function, its prior is also a Gaussian process. Computational complexity is a huge barrier here, which they address by using inducing points in the patch space, corresponding to using inter-domain inducing points (an idea which is already understood, if not by me).
-
Counterfactual Fairness - Matt J. Kusner, Joshua R. Loftus, Chris Russell, Ricardo Silva. Consider predictors as counterfactually fair if they produce the same result if a sensitive attribute were different. This means that any nodes downstream (in the causal graph) of that sensitive attribute may also be different. This implies that a predictor will necessarily be counterfactually fair if it is only a function of nodes which are not descendants of the sensitive attribute, unsurprisingly enough. They address the fact that this is rarely feasible (almost everything in a person's life may be affected by their race, for example), by considering other models. For example, using residuals of variables, after accounting for (using a linear model) the sensitive attributes. One nitpick: I take issue with the example they give in Figure 2 (level 2). They introduce a latent variable which is predictive of success (GPA, LSAT, first year law school average grade) independent of sex and race, and call this knowledge. I think this is a weird choice - surely knowledge is affected by sex/race, if only by influencing available educational opportunities and ability to study unimpeded (for example, the need to work during school/college, the need to look after family members). I am trying to think of another name for this node which is not plausibly influenced by sex or race, some sort of intrinsic attribute of the person - 'grit'? 'general intelligence'? 'luck'? (But who wants to base law school admissions on luck?) I can't imagine the authors were intending to make any kind of political statement about the nature of knowledge here, but it seems like a weird error(?) in a paper dealing with social issues.
-
Multiresolution Kernel Approximation for Gaussian Process Regression - Yi Ding, Risi Kondor, Jonathan Eskreis-Winkler. The popular method for scaling GPs is to approximate the kernel function using a low-rank approximation (the Nyström approximation). There are some issues with that: is a low-rank approximation reasonable? Which part of the eigenvalue spectrum of K' (that is, K + sigma I, which appears in the MAP estimate of the function) is the most important? This work proposes and develops a different kind of kernel approximation, depending on the data, where local factorisations are used, and it can be assumed that 'distant clusters [of data] only interact in a low rank fashion'. My cursory skim of the paper wasn't enough to get exactly what they're doing, but I love to see work questioning common practices and trying to understand/improve on them.
-
Doubly Stochastic Variational Inference for Deep Gaussian Processes - Hugh Salimbeni, Marc Deisenroth. Why do I always end up reading about GPs? I'm not even using them (right now?!). The tl;dr on this paper is that they got deep (that is, multi-layer generalisations of) GPs to work. Previously they didn't work particularly well because the variational posterior required each layer to be independent, an assumption which this work drops by introducing a new variational inference procedure (hence the title). They show that this model works even on datasets with a billion examples.
-
Style Transfer from Non-Parallel Text by Cross-Alignment - Tianxiao Shen, Tao Lei, Regina Barzilay, Tommi Jaakola. Separate content from style, in text. This is interesting to me because, like years ago, (2014) we had discussed using language embeddings to remove stylistic choices from the language of doctors, to try to standardise text across multiple authors. I'm not saying we have any claim whatsoever to the idea - ideas are cheap, implementation matters - but I'm interested to see that someone has - sort of - achieved something like what we wanted. They assume they have corpora with roughly the same content distribution but different style distributions, and try to learn a latent representation (which they formulate using a probabilistic model). I have a big armchair-linguist issue with the idea that style is independent of content, because if you consider content as meaning then a lot of meaning is conveyed through how someone says something, and indeed even in their examples, they consider 'sentiment' as style, in which case I actually don't know what they mean by content. They actually mention in the introduction that one can only hope to approximately separate style and content even with parallel data, but they never really clearly define what they mean by 'content' of a sentence.
-
Deep Multi-task Gaussian Processes for Survival Analysis with Competing Risks - Ahmed M. Alaa · Mihaela van der Schaar. The risks are competing because the patient can only die from one thing. The model attempts to produce survival times (time-to-event) using a deep, multi-task (since multiple risks) Gaussian process. They use an intrinsic coregionalisation model for the kernel functions to account for multiple outputs, which models task(=output) dependence independently of input dependence, but simplifies calculations a lot (I tried to build a more complicated multi-task kernel function once and it was a big mess). They also point out that using a deep GP alleviates some dependence on the exact form of the kernel function. This work (unsurprisingly) uses the 'old' (2013) work on deep GPs, so I wonder how much it would benefit from the improved deep GPs (see above).
-
Unsupervised Learning of Disentangled Representations from Video - Emily Denton, Vighnesh Birodkar. They want to separate time-varying and stationary parts of a video. Then you can predict future frames by applying a LSTM to the time-varying components. That's pretty neat! How do they achieve this? They use four networks - two encoders (one for scene (stationary information), one for pose (time-varying)), a decoder which maps pose and scene vectors to produce a frame, and a scene discriminator which tries to tell if pose vectors came from the same video. They construct loss terms to impose their constraints (separating time-varying and static elements), including some interesting adversarial loss terms.
Posters

My experience of the poster sessions suffered the most as a result of jetlag, so I ended up looking at far fewer posters than I would have liked (even accounting for my eternally overambitious plans for poster sessions). This was also the first year where I got invited to ~cool parties~, so I went to some of those, too.
The hall for the posters included what seemed like gratuitous space between rows, but it filled up rapidly (the crowd at the Capsules poster was sizeable). I admit I always think about roller derby these days when I'm trying to get past crowds of people, but hip checking strangers isn't a great way to do poster sessions (I assume).
My poster session strategy is the following:
- before the conference: go through the list of papers and note the interesting ones
- don't leave any time to actually read the papers
- forget about the list, fight through crowds of large men to peer at poster titles
- eventually, learn things
A humble plea to poster presenters: please don't stand directly in front of your poster while you're talking about it, I can't see and I don't want to get so close to you that you start talking to me.
Here's a little caveat about this part of the blog post: I didn't visit all these posters. I'm just taking the opportunity to mention more interesting papers.
-
The Neural Hawkes Process: A Neurally Self-Modulating Multivariate Point Process - Hongyuan Mei, Jason Eisner. Alongside optimal transport, Hawkes processes appeared in my radar of possibly-interesting terms this NIPS, so I decided to take a look at this paper. I got so engrossed that I realised I was actually reading the paper (I usually do a cursory skim to produce these summaries), so I've had to stop myself in the interest of giving other papers a chance. In short: a Hawkes process is a kind of non-homogeneous Poisson process (the rate of the process can vary in time) where events can increase the probability of future events (the events are self-exciting). In this work they generalise the Hawkes process (allowing for inhibitory events, for example) and use a continuous-time LSTM to model the intensity functions of the given events. Also, they use a meme dataset (amongst others) to train the model, so the paper includes amusing lines like
"We attribute the poor performance of the [non-neural] Hawkes process to its failure to capture the latent properties of memes, such as their topic, political stance, or interestingness".
The idea of trying to study memes computationally is funny, because even humans barely understand memes.
 Example of a typical "meme"
Example of a typical "meme"
-
Dilated Recurrent Neural Networks - Shiyu Chang, Yang Zhang, Wei Han, Mo Yu, Xiaoxiao Guo, Wei Tan, Xiaodong Cui, Michael Witbrock, Mark Hasegawa-Johnson, Thomas S. Huang. Like a dilated CNN, but... an RNN. They achieve this using dilated recurrent skip connections. This is different to the usual skip connection (which takes information from some previous state of the RNN) in that it doesn't rely on the immediately previous state. That's what makes it a dilation. You can stack layers with different dilation lengths to get a sort of 'multiresolution' RNN. If this sounds similar to the Clockwork RNN, you're right, but see section 3.4.
-
Z-Forcing: Training Stochastic Recurrent Networks - Anirudh Goyal, Alessandro Sordoni, Marc-Alexandre Côté, Nan Rosemary Ke, Yoshua Bengio. Yes, I care a lot about RNNs. I work on (medical) time series data, if that wasn't already apparent. This paper adds to the growing work on combining deterministic RNN architectures with stochastic elements (like state space models), hitting an intractable inference problem, and using variational inference with a RNN-parametrised posterior approximation. So what's new here? They observe that these models can often neglect to use the 'latent' part (the stochastic elements), so they add a regularisation term to the ELBO which 'forces' the latent state at time t to be predictive of the hidden state of the backwards-running inference network. And this works better, empirically. When I first saw this paper I panicked because the title makes it sound very similar to an idea I have been cooking up, an idea which I got stuck on because I was trying to explain an additional regularisation term in terms of a prior (on something). But these authors just go ahead and use a regulariser without any probabilistic interpretation, so it's probably fine to do that. Note to self: not everything has to be mathematically beautiful.
-
What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? - Alex Kendall, Yarin Gal. I first learned about (and immediately loved) aleatoric and epistemic uncertainty in my applied Bayesian statistics class back in Cambridge, so despite not featuring RNNs, I was interested in this work. In this context, aleatoric uncertainty is the uncertainty inherent to the observations, whereas epistemic uncertainty arises from uncertainty about the model parameters (which could in principle be reduced with more training). So this work studies epistemic and aleatoric uncertainty in deep networks (for computer vision), and shows that modelling aleatoric uncertainty improves performance in semantic segmentation and depth regression.
-
Fast-Slow Recurrent Neural Networks - Asier Mujika, Florian Meier, Angelika Steger. Phew, back to RNNs. This work proposes a RNN architecture attempting to combine the advantages of multiscale RNNs and deep transition RNNs. Basically, it's a 'new model architecture' paper. They show good results on two language modelling tasks, and do further analyses of the properties of their model. Multiscale (temporally speaking) data is extremely common in medicine, so something like MIMIC-III would have been a great test-case for this model as well. Maybe I'll find a masters student to explore this (I obviously don't have time because I spend all my time writing blog posts).
-
Identification of Gaussian Process State Space Models - Stefanos Eleftheriadis, Thomas F.W. Nicholson, Marc Peter Deisenroth, James Hensman. A lot of work focuses on inferring the latent states of a GP state space model. Here, they (also) look at learning the model itself. An important difference between your typical GP setting and the GP-SSM is that the inputs to the GP in the latter case are latent states (of the state space model), so they have to infer both the latent states and the transition dynamics (that's the model). They use variational inference with a bidirectional RNN as the recognition network, so you know I'm on board.
-
On Fairness and Calibration - Geoff Pleiss, Manish Raghavan, Felix Wu, Jon Kleinberg, Kilian Q. Weinberger. This work seems to be a follow-up to this paper which was written to analyse this piece on bias in criminal sentencing from ProPublica (ProPublica also followed up on this and other research following their investigation). So first up: it's awesome to see academic research and investigative journalism interacting in this way. In the precursor paper they provide an impossibility proof (which is given a simplified geometric proof in this paper) for simultaneously satisfying calibration and equalized odds (equal false positive and false negative rates between groups). As hinted in the precursor paper, relaxing the notion of equalized odds (for example, sacrificing equal false positive rates) may allow you to keep calibration, and that's what they show in this paper.
-
Causal Effect Inference with Deep Latent-Variable Models - Christos Louizos, Uri Shalit, Joris Mooij, David Sontag, Richard Zemel, Max Welling. The focus of this work is in account for confounders (by modelling them as latent variables) while doing effect inference, particularly in the presence of noisy proxies of true confounders. They achieve this using a 'causal effect variational autoencoder' (CEVAE).
Machine Learning for Health (ML4H)
I speculate that they're moving away from the previous acronym (MLHC - machine learning for health care) due to a collision with the MLHC conference (previously abbreviated MUCMD). Apparently MLHC (the conference) will be in Stanford in 2018, which is a shame because I feel I should attend it, but I really didn't enjoy travelling to/from California for NIPS. Also, I think conference organisers should be avoiding the USA (or any other country with restrictive or racist visa policies) if at all possible right now.
Anyway. The workshop, unrelated to the MLHC conference, was an all-day affair on the Friday of NIPS. There were all the usual things: invited talks, spotlight talks, (frustratingly short) poster sessions, and people crammed into one room for 8 hours. I missed the panel because I was stuck at lunch, and I missed Jure Leskovec's talk because I was ~ networking ~. For the rest, I took some notes.
Talks:
-
Zak Kohane - AI in Medicine That Counts. He distinguished between AI that does what doctors do, AI that does what doctors could do (but don't), and AI that does what doctors can't do. I am reminded of this post from Luke Oakden-Rayner which distinguishes between tasks we're building ML systems to solve, and tasks which doctors actually do. They're not the same, and Kohane made the point that they need not be, in general. We can see gains in outperforming doctors on e.g. diagnostics, but we can also see gains in doing analyses doctors simply can't do (because they're not computers). Kohane gave an example of a child with ulcerative colitis who was saved from colonectomy after they ran a gene expression analysis on children with similar irritable bowel disease and identified an effective drug (indirubin). He also provided a good comparison between medicine and what Deepmind has been achieving with AlphaZero (on Go and other games). Achievements like AlphaZero make people think AI is about to take over the world (from what I can tell), but medicine is far from AI-led mastery:
- it's non-deterministic
- it's not fully observable
- the action space is not discrete
- we have no perfect simulators
- 'episodes' in medicine are not short (consider the number of seconds in a typical ICU stay, consider a person's entire life...)
- evaluation is unclear and slow
- trial and error is not an option (outside of controlled trials, and even then the trial is highly constrained)
In his list he also included that we have huge datasets of human play (for games like Go), but I think medicine is getting there towards having large datasets (at least locally), so I don't count this as a fundamental limitation. He then went on to discuss the money end of medicine, which I'm not a fan of, but if you're to be pragmatic, you gotta understand the game you're playing. He made a point that we may come up with cool technology to improve medicine in different ways, but unless a business argument can be made for it, it likely won't be adopted. This is more clearly true in the US where healthcare is more of profit-oriented than in other countries (e.g. those with socialised healthcare systems) - ML4H @ Socialised Healthcare edition, anyone? We can have it in a neutral country! (Joking aside, I am legitimately interested in the opportunities for ML to benefit from and improve socialised healthcare systems - data centralisation is an obvious point, but perhaps other types of problems are more immediately pressing in systems like the NHS, than they would be in the USA...)
-
Jennifer Chayes - Opportunities for Machine Learning in Cancer Immunotherapy. The immune system is an incredibly complicated and therefore cool system, and cancer immunotherapy is a very very cool use of the immune system. With the caveat that I'm not an immunologist, the tl;dr of cancer immunotherapy is: tell your immune system to target and kill cancer cells. This may be what the immune system does already, to some extent. T-cells identify specific antigens, and direct the rest of the immune system to kill cells presenting those antigens. (How do T-cells know what to identify? The thymus is the coolest organ you've never heard of.) So the challenge is to train T-cells to specifically recognise your cancer cells, but there are lots of possible (neo)antigens. You can formulate this as a matrix completion problem (T-cells v. antigens) to predict the response of new T-cells. She also described work they did for predicting response to checkpoint inhibitors (a type of cancer immunotherapy), highlighting the value of building relatively simple models on small data.
-
Susan Murphy - Challenges in Developinging Learning Algorithms to Personalise mHealth Treatments. This was about the HeartSteps project, which tries to encourage physical activity in people who have completed cardiac rehabilitation. That is, it's an app that encourages you to go for a walk. This is a problem of sequential decision making. To maximise positive outcome (more time walking), what sort of notifications should the app send, and when? If someone is driving, you shouldn't bother them. If they just walked somewhere, or are in the middle of walking, you shouldn't tell them to go for a walk. They model it as a (contextual) bandit problem, and have to deal with noise in the data, nonstationarity (the expected reward function changes over time), and that there are longer-term delayed effects from actions. Unsurprisingly (to anyone who's used apps that send them push notifications), after a while people just start ignoring them, and the result of interventions diminish. While the intentions in this work are noble, I can see creepy unintended uses of research like this into user engagement (like this horrible startup). Technology is always a double-edged sword, but if we have to be subjected to personalised advertising and addiction mechanics in games, and so on, at least fewer people should die of heart disease, right?
-
Fei-Fei Li - Illuminating the Dark Spaces of Healthcare. I think that was the title. She spoke about three projects in healthcare that use computer vision, and the room was packed. At first I thought everyone suddenly loves healthcare, but then I remembered that Fei-Fei Li is famous. The projects were all about activity recognition from non-RGB video (they had depth sensors and IR video if I recall - these alleviate some privacy concerns). First she spoke about identifying hand-washing to tackle hospital acquired infection. One challenge was in activity recognition given unusual (for research) viewpoints, e.g. cameras on ceilings looking directly down. The second project was about ICU activity recognition, to better understand what people spend time doing in the ICU. The priority here was efficiency, so they developed methods to analyse video which don't require analysis of every single frame, saving a lot of compute while still achieving high performance (on standard video understanding datasets). Finally, she spoke about applications in independent senior living, such as fall detection. This in particular is challenging due to limited training data and rare events (thankfully). They propose to use domain transfer to aid in the data scarcity issues, but she pointed out that much of this work is still in progress.
-
Jill Mesirov - From Data to Knowledge. I am doubtful this was the title of her talk, but we'll run with it. The topic was medulloblastoma, which is one of the most common forms of paediatric brain tumour. 70% of children survive, but only 10% go on to leave independent lives. Their focus is in predicting relapse, which they achieve using a probabilistic model incorporating various clinical and genomic features. She then went on to describe a project to identify novel therapeutics for an aggressive subtype of medulloblastoma driven by Myc (this is a gene). Through mouse xenograft experiments and expression profiling, they found this subtype is likely sensitive to CDK-inhibitors, and found they could extend survival (in mice) by 20% with palbociclib, suggesting a candidate treatment. This sort of analysis is sort of 'well known' to me because my lab (alongside machine learning) works on cancer genomics, but I'd also like to pause for a moment to reflect on two things:
- As with the example from Zak Kohane (about indirubin), a lot of the time (translational) computational biologists are hunting for threads - persistent patterns in the disease which indicate possible vulnerabilities, which they can then follow up by looking for matches in drugs with known targets. If you can optimise any point in that process, you can probably save someone's life, some day.
- A 20% extension in survival is clinically significant, but it's not a cure as we think of it. For mice it's measured in days, for humans probably one or two years if not months. For some cancers, especially brain cancers, this is still where we're at. Fighting cancer is really, really hard.
-
Greg Corrado. I just stopped writing down the titles at some point. He spoke about a few different projects:
- Diagnostics: doctors working alongside algorithms to work better/faster. Examples from Google Brain: screening for diabetic retinopathy (on par with ophthamologists), reading breast cancer biopsies.
- Care management/decision support: the idea is to have smart electronic medical records, to help reduce errors and improve care quality. Having observed clinicians interacting with EMRs, I see a lot of potential for improvement here.
He mentioned challenges with processing medical data because of how messy it is and I just laughed and laughed and then cried (silently). Apparently they built some sort of FHIR-based pipeline to integrate data from six healthcare systems, and it worked well, but I didn't write down what they were doing at the end of the pipeline. He also gave a shout-out to Google's newly open-sourced variant caller, DeepVariant.
-
Mihaela van der Schaar - Dynamical Disease Modelling. Her work focuses on dynamical modelling, assuming some hidden clinical state which informs observable physiological variables. You could approach this using a hidden Markov model, but she observed that transition probabilities typically depend on sojourn times, necessitating a semi-Markov model. Furthermore, patterns of missingness are informative, suggesting to model observation times, e.g. as a Hawkes process. The informativeness of measurements in medicine may not be immediately obvious, but the rationale (at least in the ICU, my area of focus) is that some measurements are only taken when needed, and they're only needed when the doctor suspects something is up. Even if a measurement is routinely performed, the rate of measurement may increase when patients become more critical. So you have a huge case of missing-not-at-random. She also mentioned their work on modelling competing risks, which I described earlier in this blog post.
-
Atul Butte - Translating a Trillion Points of Data into Diagnostics, Therapies and New Insights in Health and Disease. I didn't take notes for this talk, but his slides are here - I'd recommend slide 29. In case that link at some point goes dead, that slide summarises lessons he's learned in MLHC over the years, and these are (paraphrased):
- Solve the problems that health care professionals need solved, don't just guess
- Watch out for models limited by bad inputs (e.g. from patients, from doctors)
- Learn what IRB, HIPAA, BAA, ICD-10 codes, CPT codes, CLIA, and CAP are.
- Learn patience.
- Not everything needs deep learning.
- Having all the data on someone is super rare.
- Health care inefficiency is not about friction. (He made a point that everywhere there's a cost, someone is making money and will push back against losing that money.)
- Data integration can happen, if there's a business reason for it.
- Platforms and companies are commoditized. (As subpoints to that he suggests the ML people should come with some medical knowledge, to demonstrate we care about healthcare, and so we don't cost medical collaborators time training us.)
Another point he made was that there's a lot of freely-accessible data out there, which is ripe for analysis. And possibly founding startups.
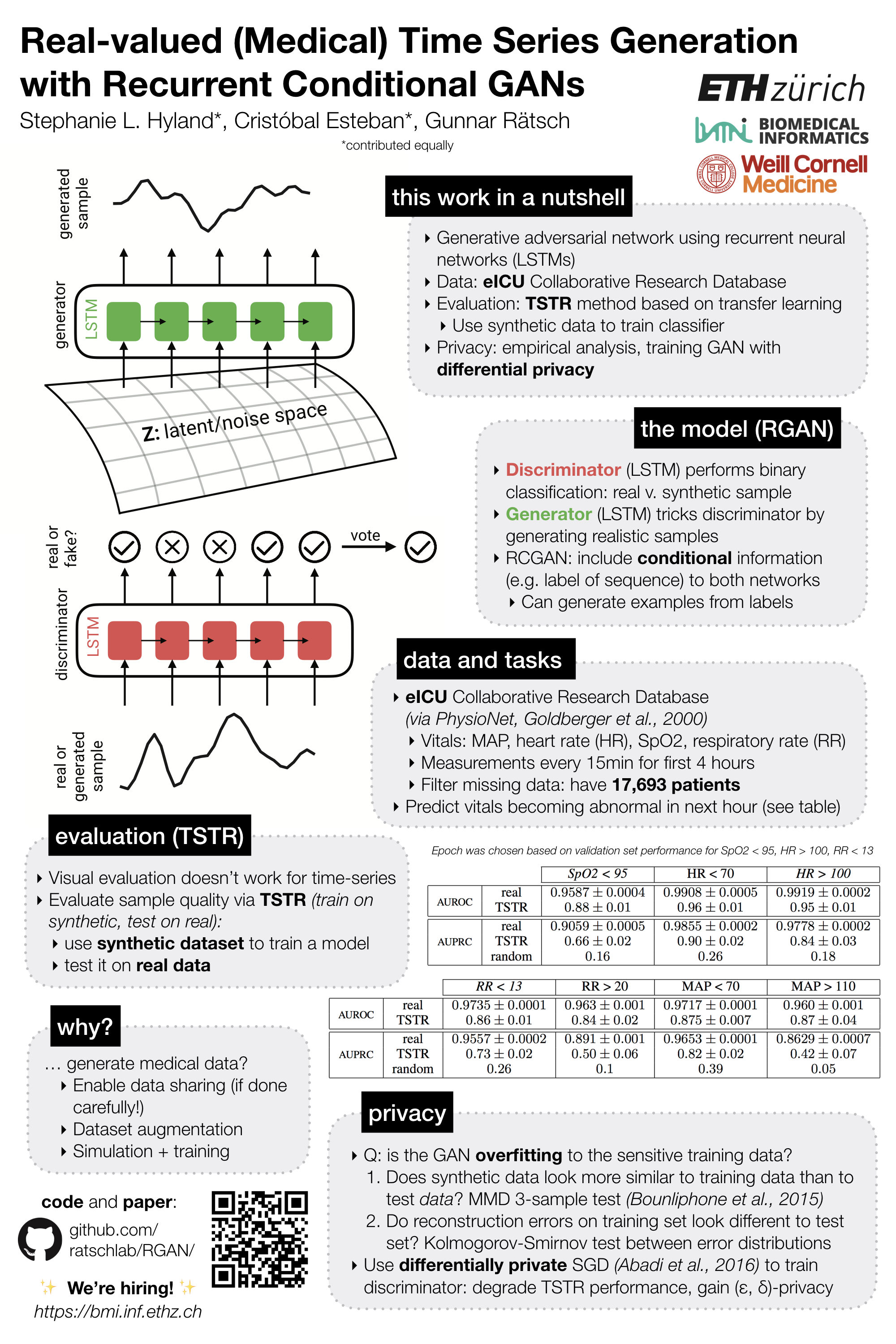
As I mentioned, there were two poster sessions. I spent the first one presenting my poster, and much of the second one talking to people, so I didn't get to see too many posters. I've described a lot of work from other people in this post, so let me do the same for myself. At WiML and ML4H I was presenting (variations on) this poster: (right)
Summary of the related paper:
-
Real-valued (Medical) Time Series Generation with Recurrent Conditional GANs - Stephanie L. Hyland (that's me) and Cristóbal Esteban, Gunnar Rätsch. (For disclosure: the version that was accepted by ML4H was a 4-page version of this preprint, focusing on the medical data and aspects. They asked us to give links to the arXiv versions of our work, but I couldn't in good faith link to the full version as it wasn't reviewed by them. In case you noticed and were wondering why there's no link to the paper the workshop page, it's because of my conscience).
The motivation for this work was that MLHC struggles with data sharing. Medical data is hard to share, with good reason. But it means a lot of work in MLHC is completely unreproducible, and nobody can directly build on it, because they don't have access to the data/task a model was built for. This stifles our progress, and MLHC is hard enough already. So wouldn't it be great if we had a synthetic dataset (without privacy concerns) that we could use to benchmark models and approaches? Shoutout to this related paper with similar motivation from Choi et al.: Generating Multi-label Discrete Patient Records using Generative Adversarial Networks (they focus on binary and count-valued data, hence our focus on real-valued time-series data).
I'd summarise what we did in this work in three points:
- Devise a GAN architecture to generate real-valued time series. We call this a 'recurrent' GAN, or RGAN, because it uses RNNs for both discriminator and generator networks (yes, RNNs!). We also have a conditional version which takes label information, allowing the RGAN to generate data from labels.
- Devise an evaluation scheme for GANs tailored to our setting. We do this by generating a synthetic training dataset from the RCGAN (labels + features), training a classifier (e.g. CNN, random forest) on it, and reporting its performance on a held-out real test set. We call this the TSTR (train on synthetic, test on real) score. Since we want to use the RGAN to generate synthetic medical data, the TSTR score is of particular relevance.
- Analyse empirically whether the RGAN is 'overfitting'. By this I mean, we ask (roughly) if the GAN is more likely to produce samples very similar to training samples than it is to produce other samples (from the same distribution, e.g. the test set). If it is, then we have a problem. Firstly because reproducing the training set is boring and does not require a GAN, and secondly (more importantly) because reproducing the training data set would constitute a serious privacy breach in our setting.
On the final point, we also experimented with training the RGAN using differential privacy, just to be extra safe. If you're willing to sacrifice performance you can get some privacy, but it's a harsh trade-off and requires further research.
I held a small reading group in my lab about interesting contributions from the ML4H workshop, so I'll briefly summarise two papers of interest to me:
-
Generative Adversarial Networks for Electronic Health Records: A Framework for Exploring and Evaluating Methods for Predicting Drug-Induced Laboratory Test Trajectories - Alexandre Yahi, Rami Vanguri, Noémie Elhadad, Nicholas P. Tatonetti. My reason for interest should be obvious. Also, the first author emailed me to get help with our code, which possibly means they used it. I spent some time answering issues on GitHub and responding to emails, and I'm still quite a junior scientist, so it's really exciting for me to see people taking interest in and actually trying to use my work. Anyways, in this paper, as far a I understand it, they're generating cholesterol time-course data before and during exposure to statins. They do two interesting things: 1) Clustering patients based on a large set of clinical attributes, then training separate GANs on each cluster. 2) Evaluating the performance of the GAN by measuring how well it 'predicts' cholesterol level during statins exposure. They do this by matching generated samples to the closest real (hopefully test-set) sample based on the pre-exposure part of the sequence, then measuring the similarity of the synthetic and real samples during statins exposure. This evaluation method seems a little brittle - imagine there are multiple real samples that look similar to the synthetic one, but respond to statins quite differently, but it's an interesting idea.
-
Personalized Gaussian Processes for Future Prediction of Alzheimer's Disease Progression - Kelly Peterson, Ognjen (Oggi) Rudovic, Ricardo Guerrero, Rosalind W. Picard. I haven't spent enough time with this paper to fully understand it, but the most interesting aspects are: fitting a GP model to a source population, and personalising (i.e. tuning) it to an individual based on their observed data to date using domain-adaptive GPs, and using auto-regressive GPs. Various kinds of GPs. No RNNs.
Conclusion
This has been an exceedingly long blog post and I hope you're not as exhausted as I am, but this is basically an accurate depiction of my experience of NIPS. A lot of stuff, all the time. I have not even mentioned the Bayesian Deep Learning workshop. During the lunch break on the final day I grabbed a burrito and almost fell asleep. I was not the only one. The convention centre by that point was gradually emptying, with scattered people dozing off in chairs, and a prominent left-luggage zone where the registration tables had been. There was a clear sense of winding down, perhaps because the process had already begun for me. I stayed only briefly at the closing party (missing some unpleasantness, it sounds like), and instead walked/skated thoughtfully back to my Airbnb along the beach, pausing to look at the stars and listen to the Pacific Ocean.
