vortidplenigilo
I have been learning Esperanto lately (see here). One of the really cool features of the language is affixes. Basically, you can create new words using some simple morphological rules, e.g.:
bona (good) → bonulo (good person)
juna (young) → junulo (young person)vorto (word) → vortaro (group of words = dictionary/vocabulary)
arbo (tree) → arbaro (group of trees = forest)
There are a lot of affixes (at time of writing I have 48 suffixes and 18 prefixes), so I thought it might be useful to write a small program to create new words by randomly attaching these affixes, then quizzing myself on them.
Here it is. (see soup.py)
Usage is like this, for example:
> soup(root=u'hundo', n_p=1, n_s=4, cheat=True)
hundo + pseŭdo : false
+ uj : container for objects described by root
+ esk : similar to/in the manner of whatever is described by root
+ eg : augments or strengthens idea shown by root affix(opposite of -et)
+ ec : quality/characteristic defined by root
pseŭdohundujeskegeco
n_p is the number of prefixes, n_s suffixes.
The cheat flag toggles printing the explanation.
So let's interpret pseŭdohundujeskegeco... this is an abstract noun, the
quality/characteristic of being a large thing similar to a container for false
dogs. Or a false quality of being a large thing similar to a container for dogs.
The order of interpretation is clear for suffixes or prefixes, I'm not sure
how to resolve it when both are present.
This is obviously a ridiculous word which no normal person would use, but I find generating and interpreting these very entertaining. Another example...
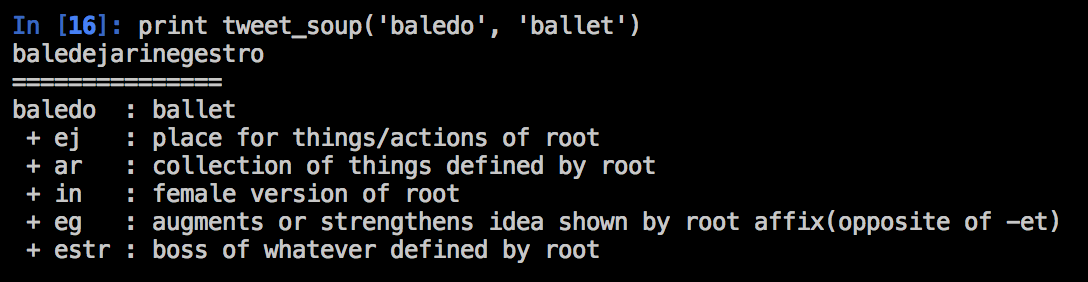
baledejarinegestro: boss of an enormous, somehow female collection of ballet theatres
I could go on all day. To save myself the effort of doing this, I automated it. So now there's a...
Twitter bot: vortidplenigilo
vortidplenigilo:
tool to make [something] full of word derivatives, from vorto + ido + plena + igi + ilo.
Every hour (or so), it tweets a random root (grabbed from a dictionary)
with a random number of suffixes and prefixes. Code is in the same repo as
before, see vortidplenigilo.py. It chooses how many affixes to use based on
two draws from Poisson distributions, preferring fewer prefixes. Since it's
limited by Twitter's 140 character limit, those with n_s or n_p above 1 tend
not to make it, unfortunately. Future work will shorten the descriptions so I
can squeeze more in. The selection of which affix is not entirely random,
however...
Making affixes make sense
Not every affix can go on every type of word. Some take nouns and output nouns,
other take nouns and output adjectives, etc. The page I grabbed the affixes from
thankfully lists which transformations are valid, so I encoded that. See affixes.py
for what is essentially a rendering of aforementioned page into python. The
sort of information I recorded is explicit in this class definition:
class affix(object):
def __init__(self, name=u'undefined',
transformations={'x': 'x'},
explanation='undefined',
conflicts={},
category='undefined'):
self.name = name
self.transformations = transformations
self.explanation = explanation
self.conflicts = conflicts
self.category = category
-
transformationsis a dict of valid word-type maps, based on word-endings (since Esperanto is so very regular in this regard). In practice these dictionaries either have one element (e.g.'a': 'o') or all ('i':'i' for 'i' in valid_word_endings), but in theory one could have an affix which turns adjectives into verbs and nouns into adjectives, I suppose. Or something like that. My code is future-proofed against complicated Esperanto dystopias. The point is that as the compound word is created, I keep track of its current 'word type' and make sure I only accept affixes which are compatible with that (and then it gets a new type from its new affix, and so on). This all takes place in themake_soupfunction insoup.py. -
explanationis just the string explaining the affix. -
conflictsis a list of other affixes (byname) which I forbid to co-exist in a compound word. The idea is to prevent illogical things like
arbarero: one of a collection of trees... a tree
dormigiĝi: to become made to be asleep... to sleep
I'm not entirely convinced I want this, though. For example,
hundetego: huge small dog
sort of makes sense. Jury is out on this decision.
- The final attribute,
category, records what type of affix it is, and is currently not used. Future version could restrict to true affixes or adjective suffixes or something. Future proof, yo. Maybe.
One of its first tweets was beautifully meta:

morfologiido: offspring of morphology
Feedback
I would gladly welcome comments/ideas on the GitHub repository,
be it language suggestions or corrections (since I am still a komencisto), code
fixes, ideas for automatically producing 'interpretations' of the generated
words, or anything else. The contents of affixes.py might also be useful
for other people doing things with Esperanto.